Unlocking Efficiency: How Hugging Face’s TOON Data Format Cuts LLM Token Usage by Up to 60%
In the rapidly evolving world of artificial intelligence, large language models are becoming central to countless applications. Yet, one persistent challenge remains — the cost of token usage. Hugging Face’s newly introduced TOON data format promises to reduce token consumption by 30 to 60%.
What is TOON and Why Does It Matter?
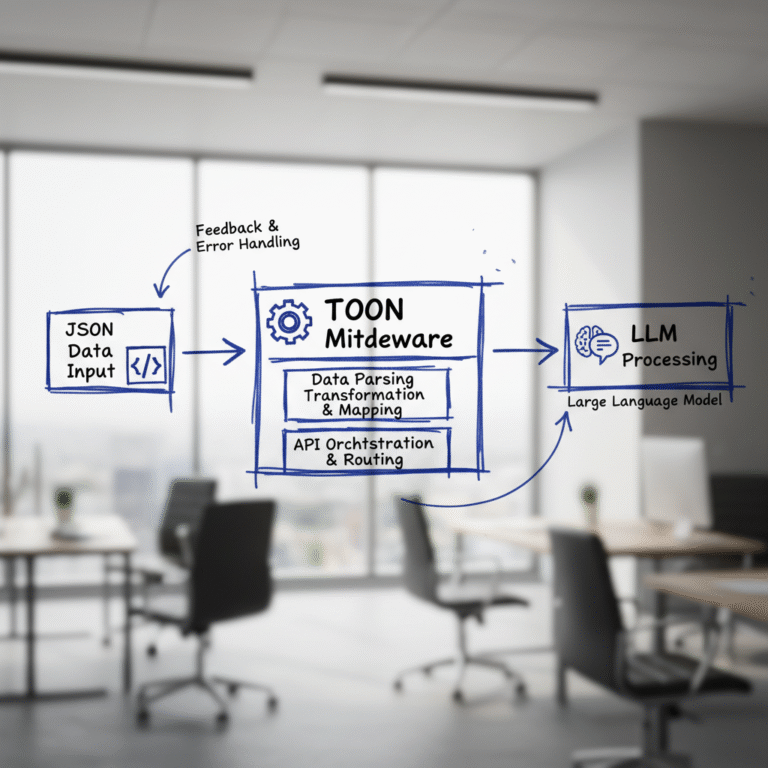
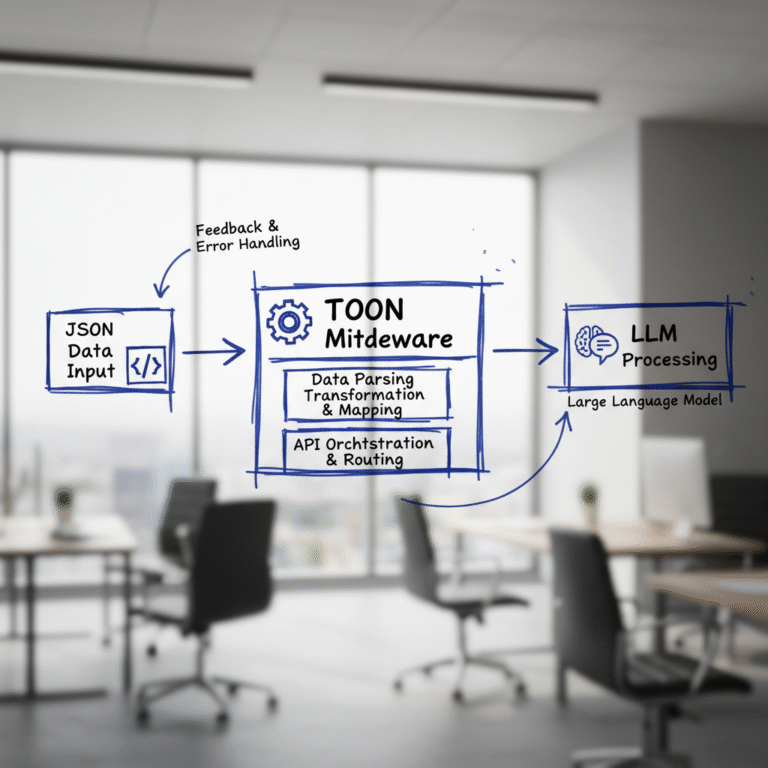
TOON is a specialized data format developed by Hugging Face designed to optimize input for LLMs. It’s a middleware layer that converts JSON structured data into a more token-efficient format right before the data reaches the model.
The Token Cost Problem
Token usage directly impacts your budget. Traditional JSON includes numerous unnecessary syntactic elements — brackets, commas, quotes — which add to token count without providing semantic value for the model.
How TOON Tackles This
TOON encodes structured data in a concise format that maintains structure and meaning while minimizing token count. This middleware approach lets developers convert existing JSON to TOON just before the input stage without overhauling infrastructure.
// Pseudo code
const toonData = convertJSONtoTOON(jsonData);
const modelResponse = await runLLMModel(toonData);
Real-World Benefits
- Cost Efficiency: A 30–60% reduction in token usage can turn previously unsustainable pipelines into profitable ones.
- Simple Integration: Acts as middleware — no major rewrite needed.
- Targeted at structured data: Logs, lists, tables — the formats where JSON is most verbose.
Conclusion
Hugging Face’s TOON data format represents a promising leap forward in managing LLM costs for structured data inputs. Keep an eye on this development and experiment with TOON in your pipelines.
For more details, visit Hugging Face’s official website.