Autoscaling Reaction Time: Why It Matters for Reliable Cloud Systems
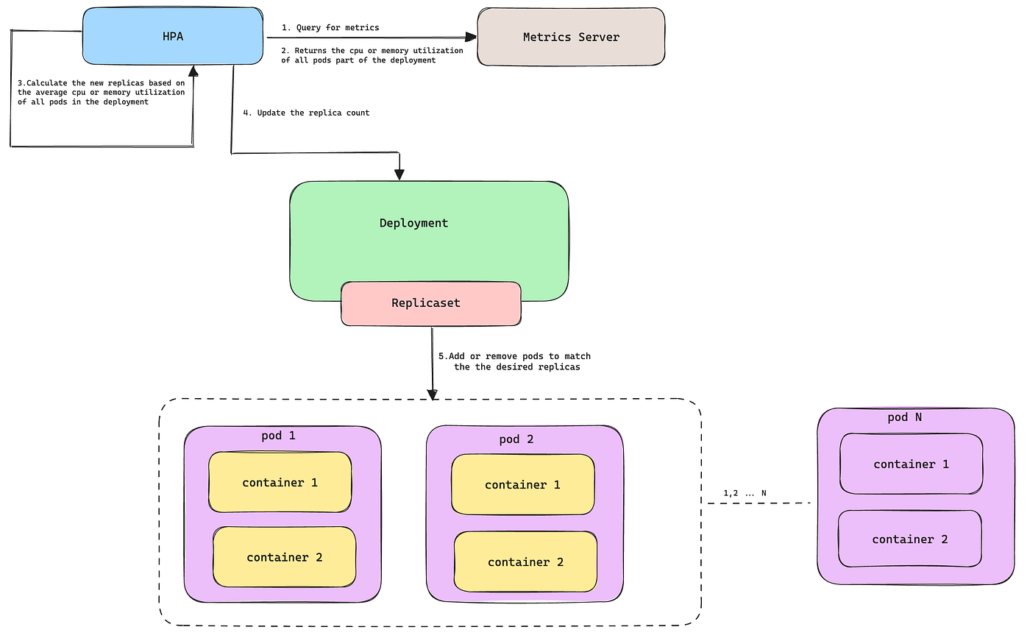
TL;DR — Autoscaling is a delayed response system, not instant elasticity — from metric detection to new capacity accepting traffic typically takes 30 seconds to 3 minutes. Understanding and designing for this reaction window is critical: systems that don’t tolerate the delay will cascade under sudden spikes before scaling even kicks in. The fix is […]
The Real Challenge of Microservices: It’s Not the Code, It’s the Coordination
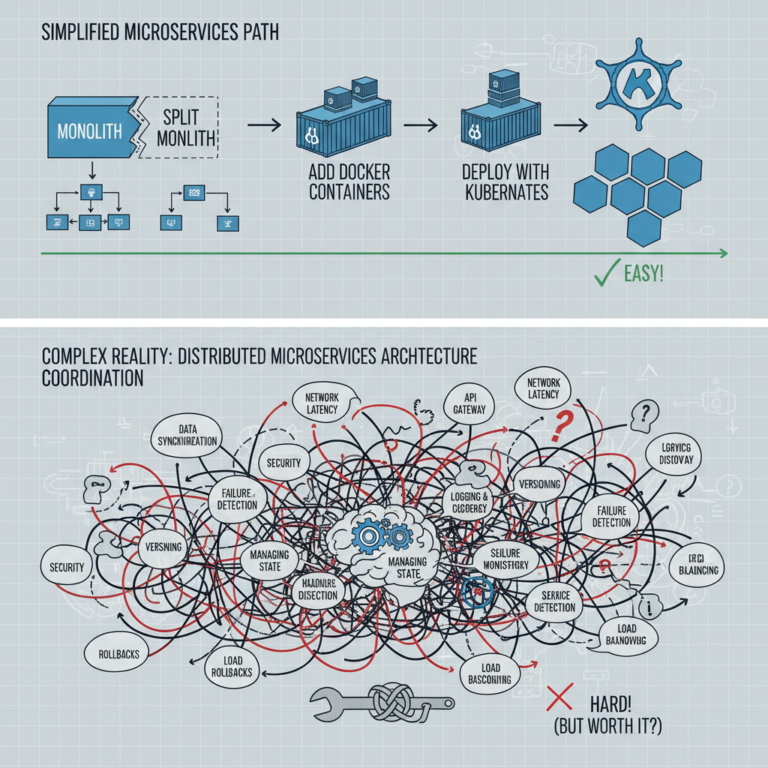
TL;DR — Splitting a monolith into microservices is just the first step — the real challenge is the coordination layer that follows: observability, secret management, distributed data consistency (Saga pattern), circuit breakers, and service discovery. Teams that succeed with microservices plan for distributed systems complexity upfront rather than discovering it after the split. microservices checklist […]
Autoscaling is Not Capacity Planning: Understanding the Differences for Optimal Performance
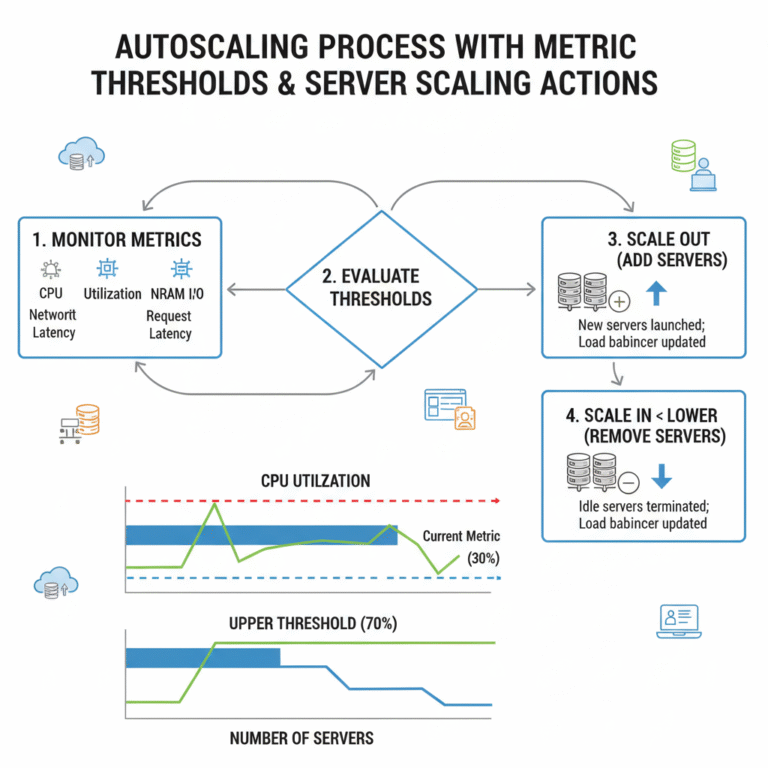
TL;DR — Autoscaling reacts to load that has already occurred — new servers take time to provision and metrics lag behind real-time demand. For predictable spikes (launches, campaigns, seasonal peaks), you need proactive capacity planning to provision resources before the event. Use autoscaling as a safety net for unexpected variance, not as your primary capacity […]
Unlocking Efficiency: How Hugging Face’s TOON Data Format Cuts LLM Token Usage by Up to 60%
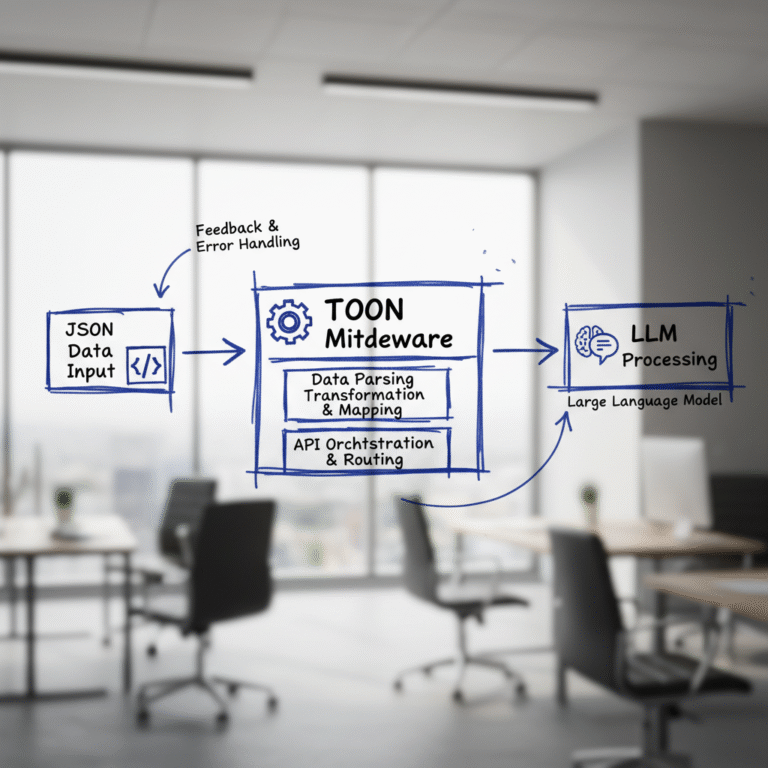
TL;DR — Hugging Face’s TOON data format acts as middleware that converts JSON structured data (logs, lists, tables) into a more token-efficient representation before it reaches your LLM — cutting token usage by 30–60%. It drops in between your existing data pipeline and your model call with no infrastructure overhaul required. Unlocking Efficiency: How Hugging […]
Shrink Your Docker Image by up to 95% — Boost Efficiency and Security!
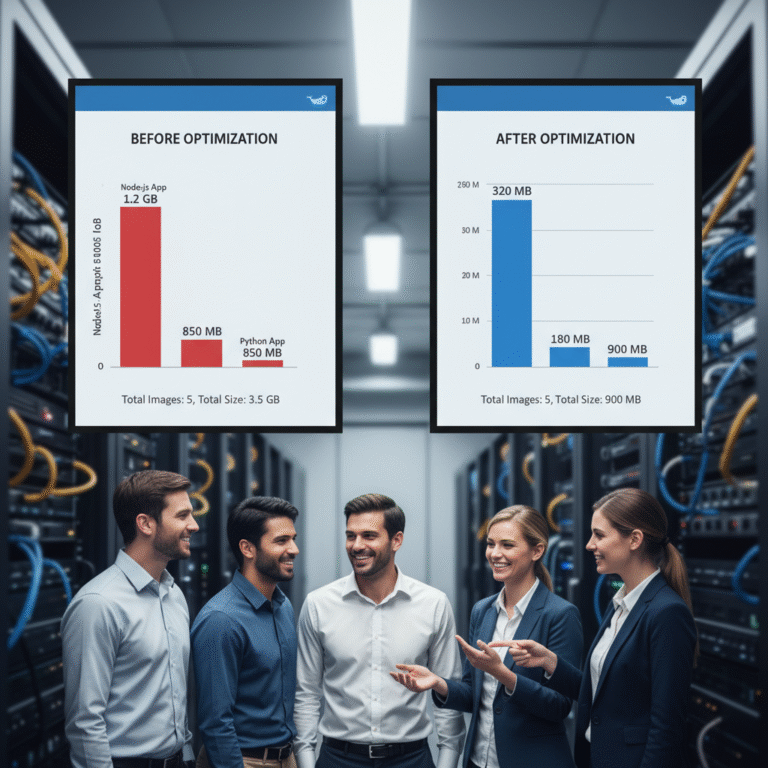
TL;DR — Bloated Docker images slow deployments, waste storage, and widen your attack surface. Using multi-stage builds, minimal base images (Alpine/distroless), combined RUN layers, and a non-root user can shrink images by up to 95% — faster deploys, lower costs, and better security with no change to application behavior. Shrink Your Docker Image by up […]
How We Reduced a Client’s Cloud Bill by 98.6% Overnight: A FinOps Case Study
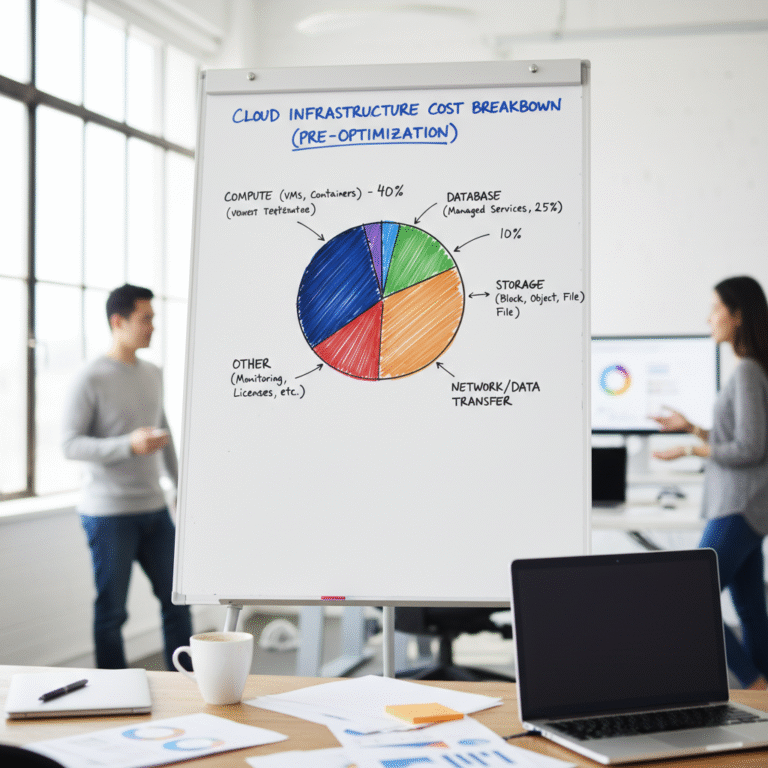
TL;DR — A client was spending $701/month on a full Kubernetes-based Discourse stack — for a forum with discussions disabled. By asking “do we even need a forum engine?”, we migrated the content to a static site on S3 + CloudFront and cut the bill to ~$10/month: a 98.6% reduction overnight. The biggest FinOps wins […]
Windows Containers: The Hidden Backbone of Enterprise Modernization

Windows Containers: The Hidden Backbone of Enterprise Modernization Windows containers often evoke a mixed bag of emotions in the enterprise tech world. Despite making up only 10-15% of container deployments, they are a critical component in modernizing legacy Windows applications without a complete system overhaul. Let’s delve into why Windows containers matter, their current landscape […]
