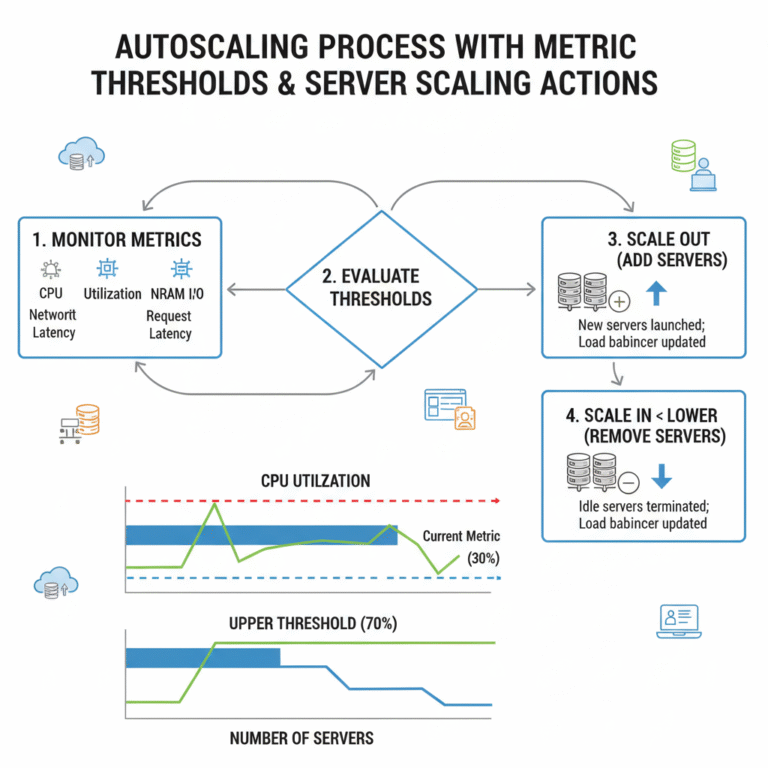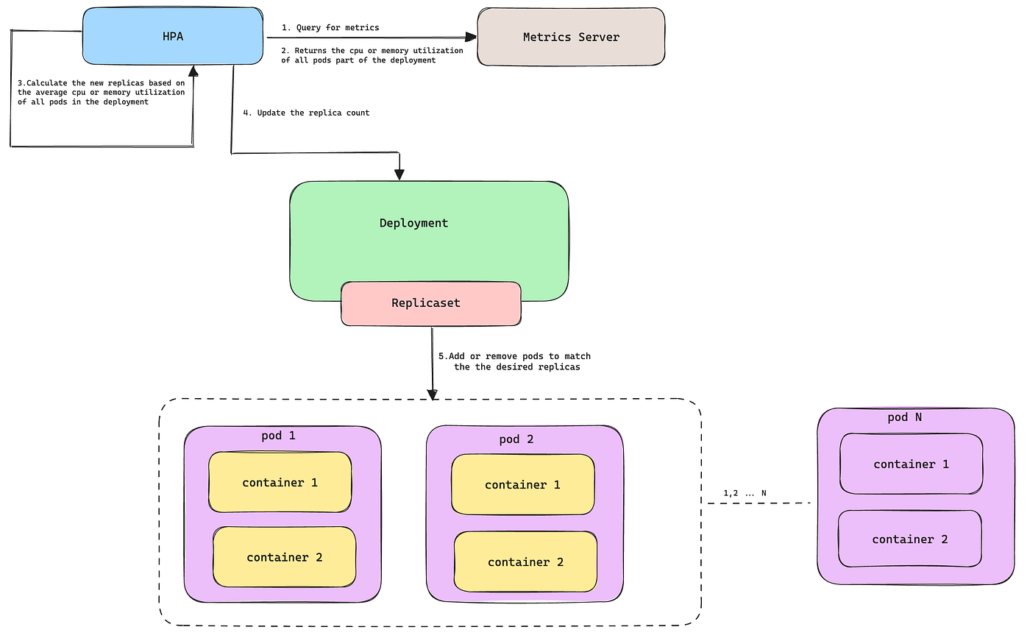
Modern distributed systems are expected to handle sudden traffic spikes without downtime. Autoscaling solves part of that problem by automatically adding or removing compute resources based on demand. The hidden variable most teams underestimate is autoscaling reaction time.
Autoscaling reaction time is the delay between a load increase and the moment new capacity becomes available and ready to serve traffic. If this delay is too long, users experience latency spikes, timeouts, or cascading failures.
What Is Autoscaling Reaction Time?
In practice, reaction time often ranges from 20 seconds to several minutes, depending on infrastructure design. Each stage of the pipeline — metric collection, policy evaluation, provisioning, startup, health checks — adds latency.
Why Reaction Time Breaks Systems
Autoscaling is often treated as a magic safety net. In reality it behaves more like a delayed response mechanism. If traffic suddenly doubles in under ten seconds and scaling requires two minutes, the system must survive that entire window with existing resources. Request queues grow, latency increases, database connections saturate, and retries amplify load — a traffic amplification cascade.
Strategies to Reduce Autoscaling Reaction Time
Faster Metrics: Reduce scrape intervals from 60 seconds to 10 or 15 seconds.
Predictive Scaling: Provision capacity before the spike based on historical patterns — daily traffic peaks, scheduled events, marketing campaigns.
Lightweight Containers: Minimal base images, faster dependency loading, and no expensive startup scripts.
Warm Capacity: Keep a small buffer of unused resources to absorb spikes instantly while scaling catches up.
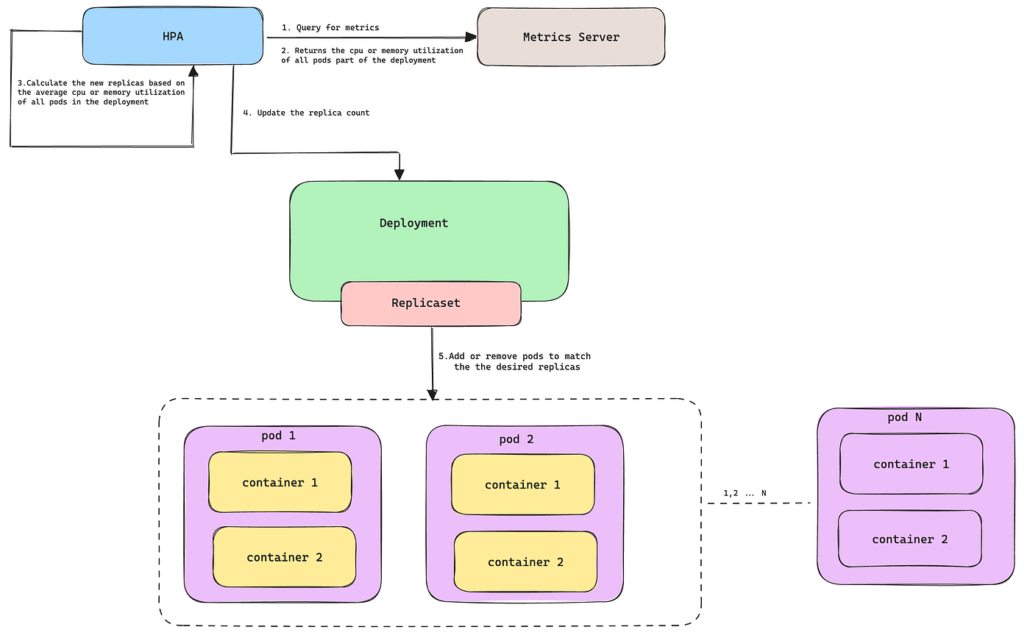
The Engineering Reality
Autoscaling is not instantaneous elasticity. It is a delayed response system operating under imperfect information. Reliable cloud architectures assume scaling delays will happen and design systems that remain stable during that window. Queues, rate limiting, circuit breakers, and backpressure mechanisms help services survive until new capacity becomes available.
Design systems that tolerate the delay and autoscaling becomes powerful. Ignore it and autoscaling simply fails slower than manual intervention.