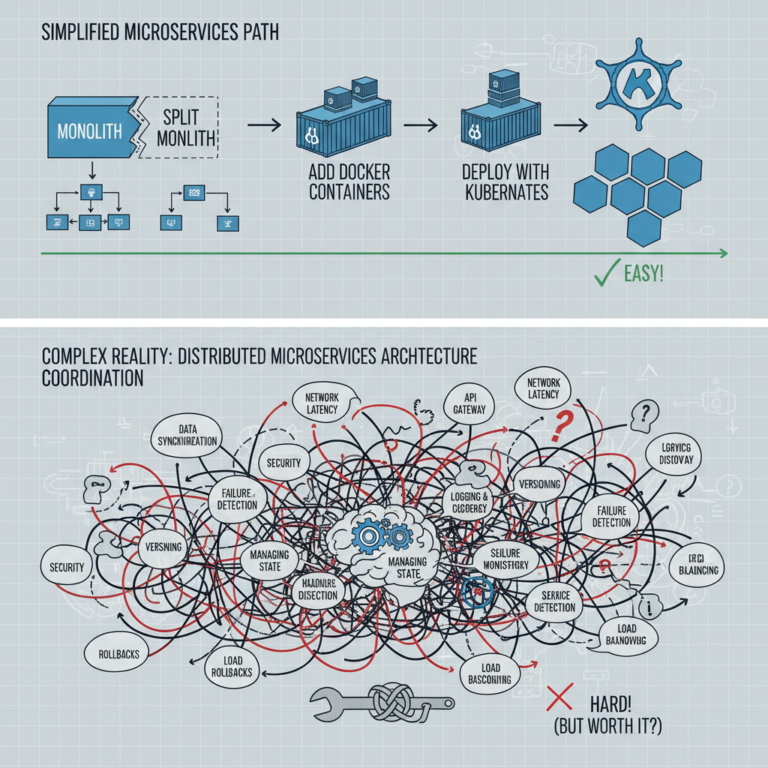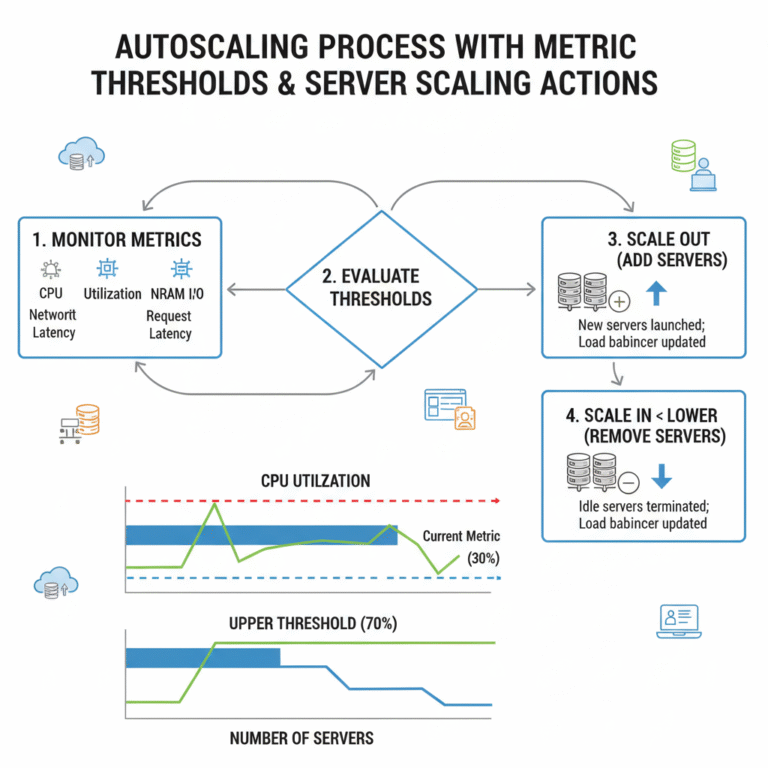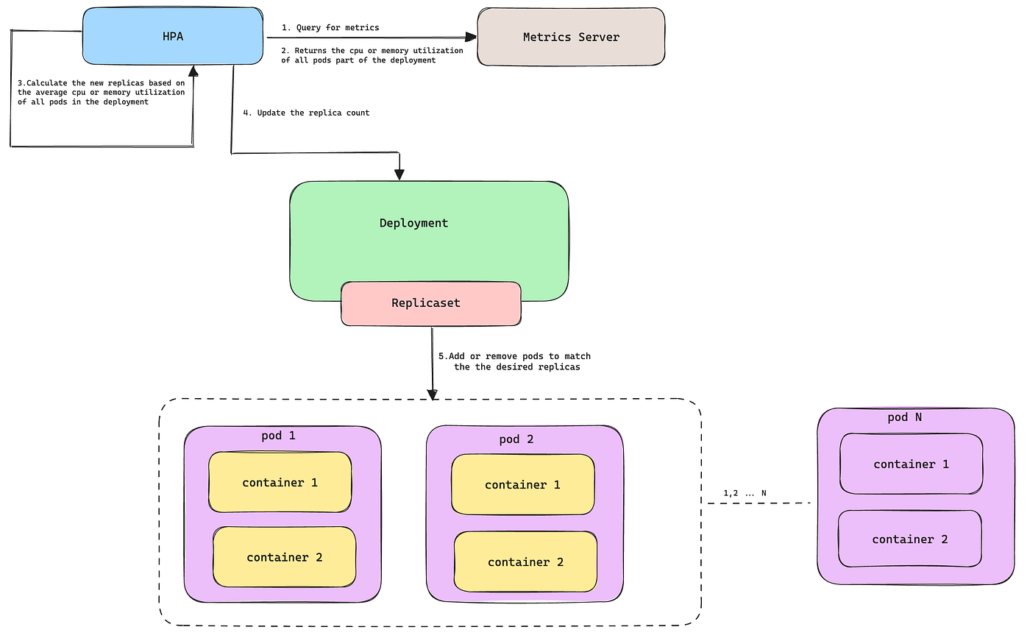
Moderne verteilte Systeme müssen plötzliche Traffic-Spitzen ohne Ausfallzeiten bewältigen. Autoscaling löst einen Teil dieses Problems automatisch. Die versteckte Variable, die die meisten Teams unterschätzen, ist die Autoscaling Reaktionszeit.
Was ist die Autoscaling Reaktionszeit?
Die Reaktionszeit beschreibt die Gesamtzeit, die eine Infrastrukturplattform benötigt, um eine erhöhte Last zu erkennen und zusätzliche Kapazität bereitzustellen. In der Praxis liegt sie oft zwischen 20 Sekunden und mehreren Minuten.
Warum 2-3 Minuten kritisch sind
Wenn der Traffic sich in unter zehn Sekunden verdoppelt und das Scaling zwei Minuten braucht, muss das System dieses Zeitfenster mit vorhandenen Ressourcen überstehen. Anfrage-Warteschlangen wachsen, Latenz steigt, Datenbankverbindungen erschöpfen sich — eine sogenannte Traffic-Amplifikations-Kaskade.
Kubernetes, Nomad und OpenShift
Kubernetes nutzt den Horizontal Pod Autoscaler (HPA). Auch in optimierten Clustern dauert der Prozess 30-90 Sekunden. Container-Skalierung benötigt 5-20 Sekunden, VM-Bereitstellung 1-3 Minuten.
Strategien zur Verbesserung
Schnellere Metriken: Scrape-Intervalle von 60 auf 10-15 Sekunden reduzieren. Prädiktives Scaling: Kapazität vor dem Spike bereitstellen. Leichtgewichtige Container: Minimale Basis-Images verwenden. Warm Capacity: Einen Puffer ungenutzter Ressourcen vorhalten.
Fazit
Autoscaling ist keine sofortige Elastizität. Zuverlässige Cloud-Architekturen müssen die Verzögerung einkalkulieren und Systeme bauen, die während dieses Zeitfensters stabil bleiben. Circuit-Breaker, Rate-Limiting und Backpressure helfen dabei.
Verwandter Artikel: Autoskalierung ist nicht Kapazitätsplanung — Die Unterschiede verstehen